


Spark Architecture and Execution
A primer on the Spark Architecture and cluster concepts such as Resilient Distributed Datasets, Data Frames,Cluster Managers, Drivers, Executors, etc


Table of contents
What is Spark?
Spark is a distributed computing framework capable of processing vast amounts of data by scaling out, rather than up, to increase processing capacity.
Spark supports performing ingestion, transformation and aggregation on batch workloads such as large immutable files and streaming workloads such as telemetry events published by IoT devices.
In the world of computing, buying bigger is generally more expensive than buying more; for example, buying one stick of 256 GB RAM is more expensive than two sticks of 128 GB. Spark lowers the barrier to entry to leverage this economy, making it easier to use multiple machines together to achieve big data processing tasks.
Spark abstracts away some computer networking, resource allocation, data partitioning and shuffling, optimising queries, etc, allowing you to focus on the application logic.
Spark is a highly configurable Scala application running on the JVM that provides APIs in multiple languages such as Scala, Java, Python, SQL or R.
What is PySpark?
PySpark is the Python API to Spark. It allows you to write Spark operations using Python. Under the hood, two processes are spun up: one is a Python process, and another is the JVM process, with the communication between the two facilitated by Py4j.
How does Spark work?
Although Spark can run on a single machine, it is intended to work on a cluster of networked machines.
Spark will translate your code into a DAG of stages and tasks and distribute their execution across the nodes in the cluster, reporting back any results and execution metrics.
Spark Runtime Architecture

Application: A Spark application consists of a driver program and executors on the cluster to execute tasks.
Driver Program: The driver program is the entry point for an application; it is where the Spark Session, Spark Context and RDDs are created. Its main responsibility is to convert your user code into tasks and schedule those tasks for execution onto the fleet of executors. The driver program stores RDD and partition metadata and exposes running Spark application information via port 4040.
Executor: The executor is a process launched for an application that runs within a Spark worker node on the cluster and is responsible for executing tasks. Executors provide the necessary interfaces for tasks to work, such as in-memory storage for RDDs or disk storage. Multiple executors can coexist on the worker nodes if multiple applications run concurrently within the cluster, as each application has its own set of executor processes.
Task: The task is a unit of work sent by the driver to be executed on an executor.
Job: "A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g.
save,collect); you'll see this term used in the driver's logs." [ref] This is the DAG created by Spark from your user code.Stage: "Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs." [ref]
Cluster Manager: This external service is responsible for acquiring resources on the Spark cluster and allocating them to a Spark Job. The currently supported Cluster Manager Types are Standalone, Hadoop YARN and Kubernetes. All of the supported Cluster Manager Types can be launched on-premise or in the cloud.
Master node: The master node is responsible for fault tolerance, task coordination, and tracking the status of Spark applications. It also acts as the master to the worker nodes in a master/slave networking topology. It can act as the Cluster Manager depending on the Cluster Manager Type. Cluster information can be accessed through port 8080.
Worker node: Any node in the Spark Cluster that is connected to the Master node and is not the Cluster Manager or Master Node and can spawn Spark executor processes to run Spark tasks.
Deploy Mode: "Distinguishes where the driver process runs. In "cluster" mode, the framework launches the driver inside of the cluster. In "client" mode, the submitter launches the driver outside of the cluster." [ref]
Tasks could run on any worker node within the cluster; every executor process must have access to any resource, such as a networked hard disk or a Python library. For example, if you use Pandas in PySpark, every worker node must have Pandas installed, or if you read from hdfs://nn1home:8020/foo.txt then that path must be available to every worker node.
Due to Spark's pluggable architecture, different tools can be used as cluster managers. Some of these tools, such as Kubernetes, are distributed computing tools with their own idioms, configurations and capabilities.
Depending on the cluster manager type and configuration depend on how the Spark cluster will operate, and the responsibilities between the Driver, Master Node and Cluster Manager can become blurred. For example, the Standalone cluster manager type is the one provided by Spark, and when used, the cluster manager acts as both the cluster manager and the master node, which is not the case for the Kubernetes cluster manager type.
Although the cluster manager type and cluster configuration can influence elements of how the Spark cluster operates, concepts such as the Applications, Driver Program, Executors, Jobs, Tasks, Stages and Deploy Modes are the same in all scenarios. Spark itself is just a scala application running on the JVM; when it's a worker node, it's the same thing, just running in "worker node" mode.
Standalone Cluster Manager
The Standalone cluster manager is simple and easy to understand and get started with. However, you have more responsibility when it comes to scaling physical resources. For example, you can have a cluster with three worker nodes, but it is up to you to decide how and when to add a fourth or scale down to two. Remember, Spark is just a scala application.
This is what a scenario with four Linux machines running a Standalone cluster manager, one running Spark as a master node and three running Spark as worker nodes, would look like:

The number of nodes is fixed, but the number of executors is dynamic based on the number of running applications, so there could be scheduling issues if the number of executors required exceeds the physical resource available across the cluster. Worker nodes are resilient, so if one fails, then the tasks are reallocated by the master to another worker node. However, the master node could be a single point of failure because it's used for scheduling, so no applications can be started if this goes down. A high-availability cluster can be configured by introducing zookeeper to manage standby master nodes.
Kubernetes Cluster Manager
With Kubernetes knowledge and the correct configuration, this cluster manager type allows you to leverage Kubernetes' dynamic scaling capability to scale the physical resources. If your Kubernetes cluster is configured to add more nodes to the cluster after the memory usage reaches a certain threshold, then as you add more Spark Applications causing you to reach that threshold, Kubernetes will scale to meet the demand.
Within a Kubernetes environment, elements of a running Spark application, such as the driver program and executors, are containerised.
When a Spark application is submitted to Kubernetes, Spark will create a k8s pod running the driver program, spawning and orchestrating more k8s pods running executors that execute the tasks. Worker nodes, in this case, are k8s pods.
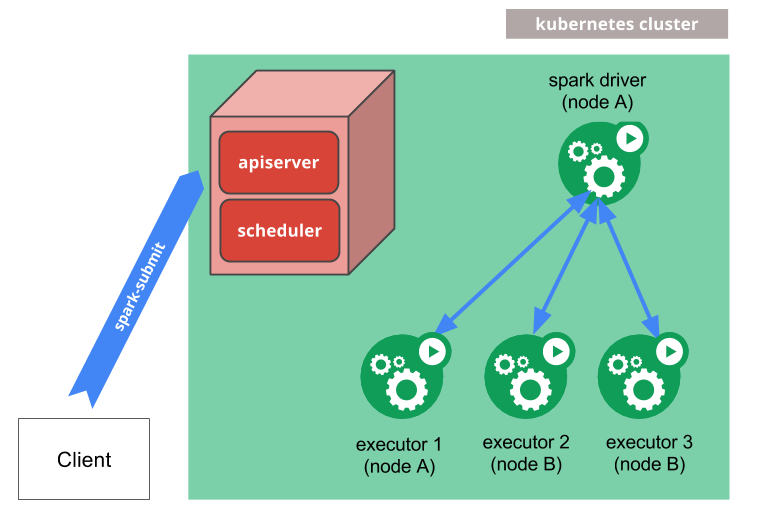
More information on how Spark works on Kubernetes can be found in the Spark official documentation.
Cloud Cluster Managers
Being open source with a pluggable architecture, some vendors have added their own proprietary components to enrich the base Spark capability. For example, Spark clusters running on AWS EMR offer auto-scaling capabilities that dynamically adjust compute resources based on the applications' demand to manage costs and AWS SDKs installed on worker nodes to make working within the wider AWS ecosystem easier. Databricks provides integrated workbooks and a proprietary metastore.
Deploy Modes: Client Mode vs Cluster Mode
"Distinguishes where the driver process runs. In "cluster" mode, the framework launches the driver inside of the cluster. In "client" mode, the submitter launches the driver outside of the cluster."[ref]
This concept is all about where the driver program lives for the duration of a Spark application's lifetime, in the cluster or out.
Client Mode
When Spark is installed on a server somewhere or on your local machine, it's also installed with Spark Shell and an interactive shell application similar to other REPL applications, such as the dev console within your web browser or the Python REPL.
Imagine running the Spark shell on your local machine but connected to a remote Spark cluster in the cloud. When you execute commands in the REPL and see the results, the query is being executed in the cloud; however, the instructions are being interpreted within the shell; the shell is the client and where the driver program is running.

This mode is great for scenarios requiring interactivity and real-time feedback, such as ad-hoc data analysis, debugging, Jupyter Notebook and development environments.
Because the application and driver program run outside of the Spark cluster, anything affecting the client will impact the application run, such as going off for lunch and letting your laptop sleep.
Cluster Mode
This is the deployment where the application and driver program run inside the Spark cluster, typically within a worker node, but it does depend on the cluster manager type.
Applications typically start from outside of the cluster by using a command called spark-submit. Once submitted, Spark will create the application and driver within the cluster.
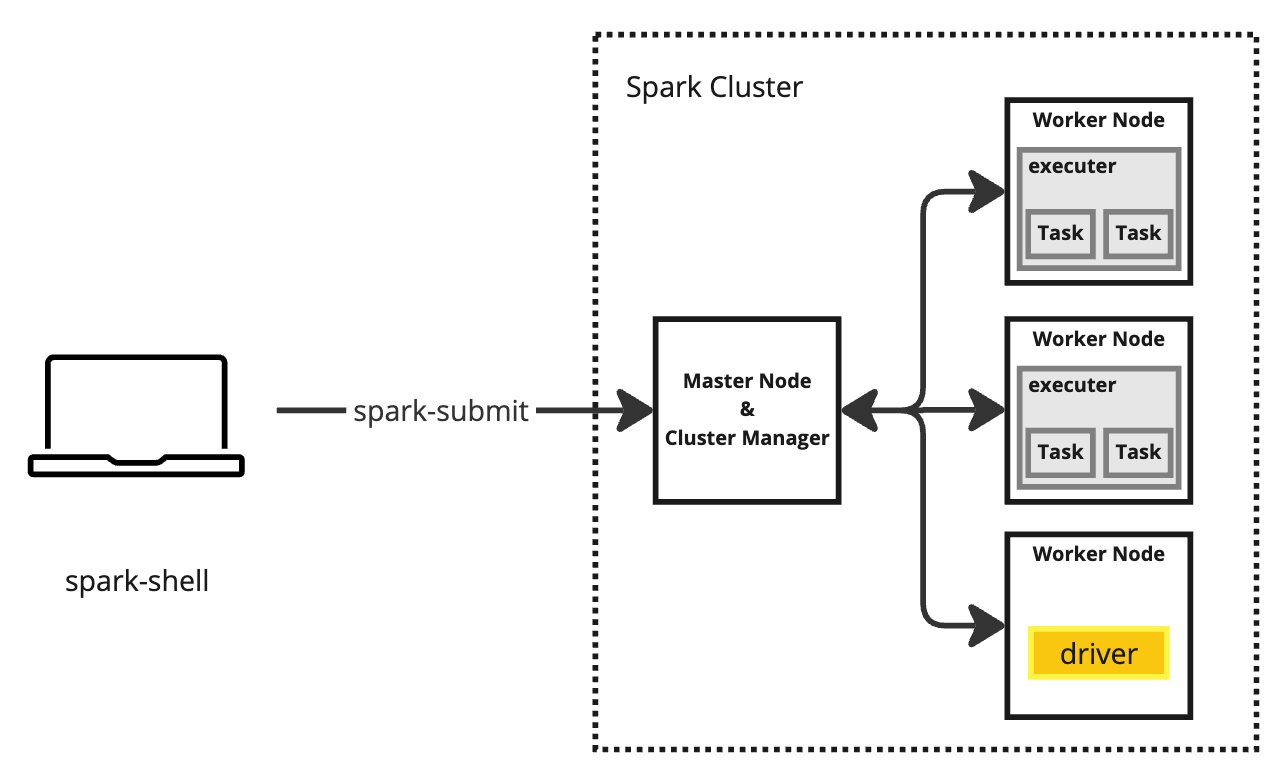
Spark applications can be submitted from a user manually using the Spark shell, but in typical production environments, it would be done by some Job scheduler, such as Apache Airflow, based on a trigger or time-based schedule depending on the nature of the Spark Job.
Core Data Structures
When writing code to run in Spark, you'll most likely be working with one of the three data structures provided by Spark. Each one has its own strengths and weaknesses.
You load your data into these data structures and apply your transformations and operations to them.
Resilient Distributed Dataset (RDD)
"Spark revolves around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat." [ref]
An RDD is an abstraction provided by Spark, a distributed collection of objects that can be processed in parallel; you can think of it as a collection, list or array and operate on it as such using transformations like filter() or map().

Here is a simple PySpark example of creating an RDD:
data = [1,2,3,4,5,6,7,8,9]
rdd = spark.sparkContext.parallelize(data)
Beneath the abstraction, Spark will create metadata about partitioning and distributing the dataset elements across the cluster for processing.
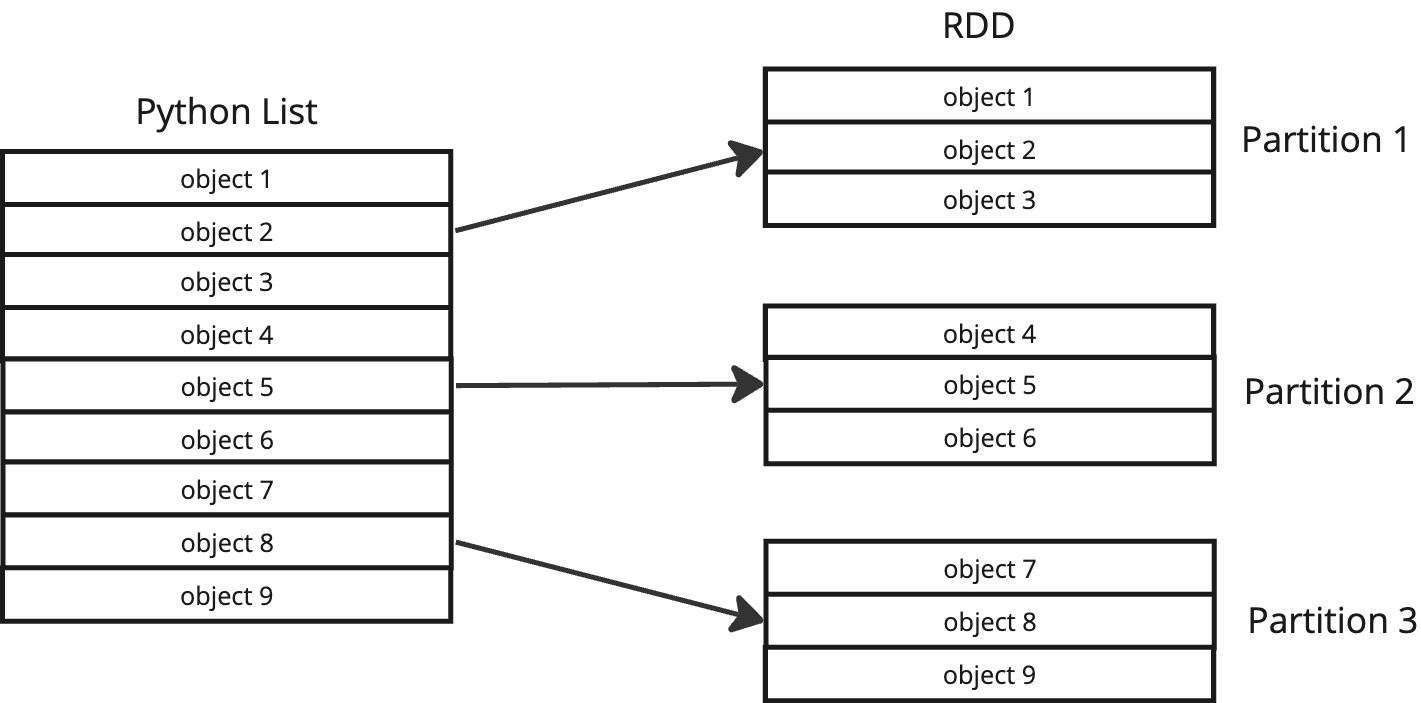
Even files read from disk, such as large CSV files distributed across the Hadoop file system, can be considered an array or collection where each line in the CSV file can be treated as an element in an array.
RDDs are well-suited for data that doesn't fit into a structured schema, like unstructured and semi-structured data, and they provide a low-level API with complete control over data and transformation operations, offering flexibility and customizability.
Data Frame
Inspired by Pandas DataFrame, the Spark DataFrame is another abstraction Spark provides. Like an RDD, it is a distributed collection of data that supports various data formats (like JSON, CSV, and Parquet) and sources (such as HDFS, Hive tables, local files, and cloud storage like AWS S3). In fact, Spark DataFrames are translated into RDDs under the hood by Spark's "Catalyst Optimizer" [ref].
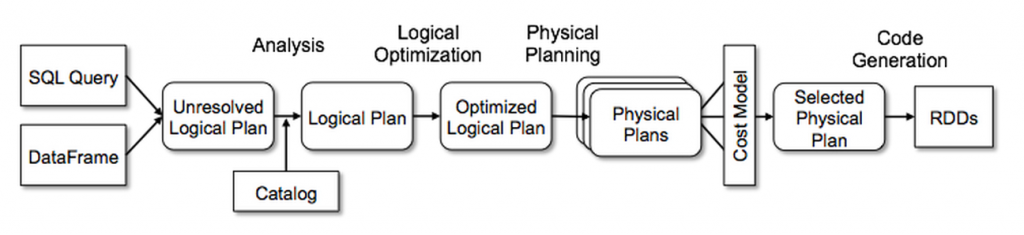
However, unlike an RDD, the Spark DataFrame is organized into named columns, conceptually equivalent to a table in a relational database and even provides a schema of the data stored within the DataFrame.

Like Pandas DataFrames in Python, operations and transformations are typically applied on the columns or the data frame as a whole, and accessing records horizontally (record-by-record or row-by-row) is not as typical as with an RDD.
Unlike Pandas DataFrames in Python, Spark DataFrames are distributed across a cluster, enabling high-performance parallel processing on large datasets. Pandas DataFrames excel at processing data that can fit into the RAM of a single machine; PySpark has the capability of transforming between Pandas and Spark DataFrames, allowing you to leverage the power of Pandas when working on a partition of data from a Spark DataFrame.
The DataFrame is part of Spark's SQL module and is well-suited for working with structured and tabular datasets. The DataFrame API provides SQL-like querying capability, making it easy for those familiar with relational databases to perform operations such as filtering, grouping and sorting.
The DataFrame was developed to overcome some of the limitations of the RDD, such as handling structured data, input and query optimisation and memory management. The DataFrame has become the dominant data structure and API in Spark, particularly in PySpark, partly due to accessibility to those familiar with SQL and Pandas.
Here's an example of how to create a Spark DataFrame with PySpark:
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
data = [("James","","Smith","36636","M",3000),
("Michael","Rose","","40288","M",4000),
("Robert","","Williams","42114","M",4000),
("Maria","Anne","Jones","39192","F",4000),
("Jen","Mary","Brown","","F",-1)
]
schema = (
StructType([
StructField("firstname",StringType(),True),
StructField("middlename",StringType(),True),
StructField("lastname",StringType(),True),
StructField("id", StringType(), True),
StructField("gender", StringType(), True),
StructField("salary", IntegerType(), True)
])
)
df = spark.createDataFrame(data=data,schema=schema)
df.printSchema()
df.show(truncate=False)
And this is what the output would look like:

Dataset
The Dataset extends the existing DataFrame API, aiming to be the best of both worlds with an optional schema.
Datasets are strongly typed and could be treated as Array<T> objects, capable of catching some errors at compile time.
However, Datasets are only available in Java and Scala and not PySpark.
Query Execution
Now that we've covered Spark concepts, architecture, and the core data structures, let's walk through how a Spark query would be broken down and executed in a distributed fashion.
Let's imagine we have a CSV file that represents the stock in a warehouse that looks something like this:
| Type | Name | Stock (KG) |
| Fruit | Banana | 10 |
| Bread | Sourdough | 4 |
| Vegetable | Carrot | 30 |
| Fruit | Orange | 20 |
| Bread | Brioche | 8 |
| Vegetable | Onion | 60 |
| Fruit | Pineapple | 16 |
| Bread | Rye | 8 |
| Vegetable | Cucumber | 40 |
And a Spark application running three executors, and we want to perform a query that gives us the total KG of stock for everything in the warehouse that is not of the type "Bread", the PySpark query would look something like this:
from pyspark.sql.functions import sum
df = spark.read.csv(
path="/warehouse/stock.csv",
header=True,
inferSchema=True
)
(
df
.filter(df["Type"] != "Bread")
.select(sum(df["Stock (KG)"]))
).show()
The driver programme will break down these instructions to distribute the tasks across the executors, which would look something like this:

So, Spark actually breaks down the data frame and applies the processing on partitions or chunks of the data frame within each executor. Spark works hard behind the scenes to create an optimised plan before actually executing any work.
.show() method. On the other hand, transformations such as the map(), filter(), or select() functions create new immutable data collections from the existing ones. Transformations in Spark are lazy, which means their results are not computed on executors immediately. Only when an action is applied is the entire query translated for execution.Summary
Spark is a distributed computing framework for handling vast amounts of data. It simplifies big data processing by abstracting complex aspects like networking and resource allocation. PySpark allows Spark operations to be written in Python.
Spark's architecture involves a driver program, executors, tasks, jobs, stages, and cluster manager. Understanding its core functionalities is crucial for leveraging its capabilities. Spark offers different data structures suited to different data types, including RDDs and DataFrames.